

Codex beats ChipWits
My journey of using codex to beat ChipWits on Steam.

TL;DR:
I wanted to see if an AI agent could beat a colleague’s game, but also beat public benchmarks for it, with a lean harness.
I’ll go over my entire journey, from having the AI agent not being able to do anything to it being able to clear the game very easily with a few markdown files that it kept with tips and tricks.
I’ll also go over beating public benchmark scores. Going to share how Codex was able to beat 2 of these, one on its own and another by looking into the winning solution and optimizing it.
AGI is coming… with a strong model (intelligence) and tools + data, there will likely be few tasks that a human can perform that an agent won’t be able to.
A few years ago I demo’ed OpenBB to someone at a hedge fund. After the meeting was over, we kept chatting in the elevator and he mentioned he was working on a game.
We reconnected a few months ago, and I asked him about the game he built and it was live!

You can test the demo version for free here: https://store.steampowered.com/app/2330720/ChipWits/
We started talking about how AI was impacting the building of the game. Email from the creator:
I couldn’t help myself. That night “I” had a first crack at it.
The game was really fun, but I wanted to try to solve it with an agent.
Then the day after I messaged him with:
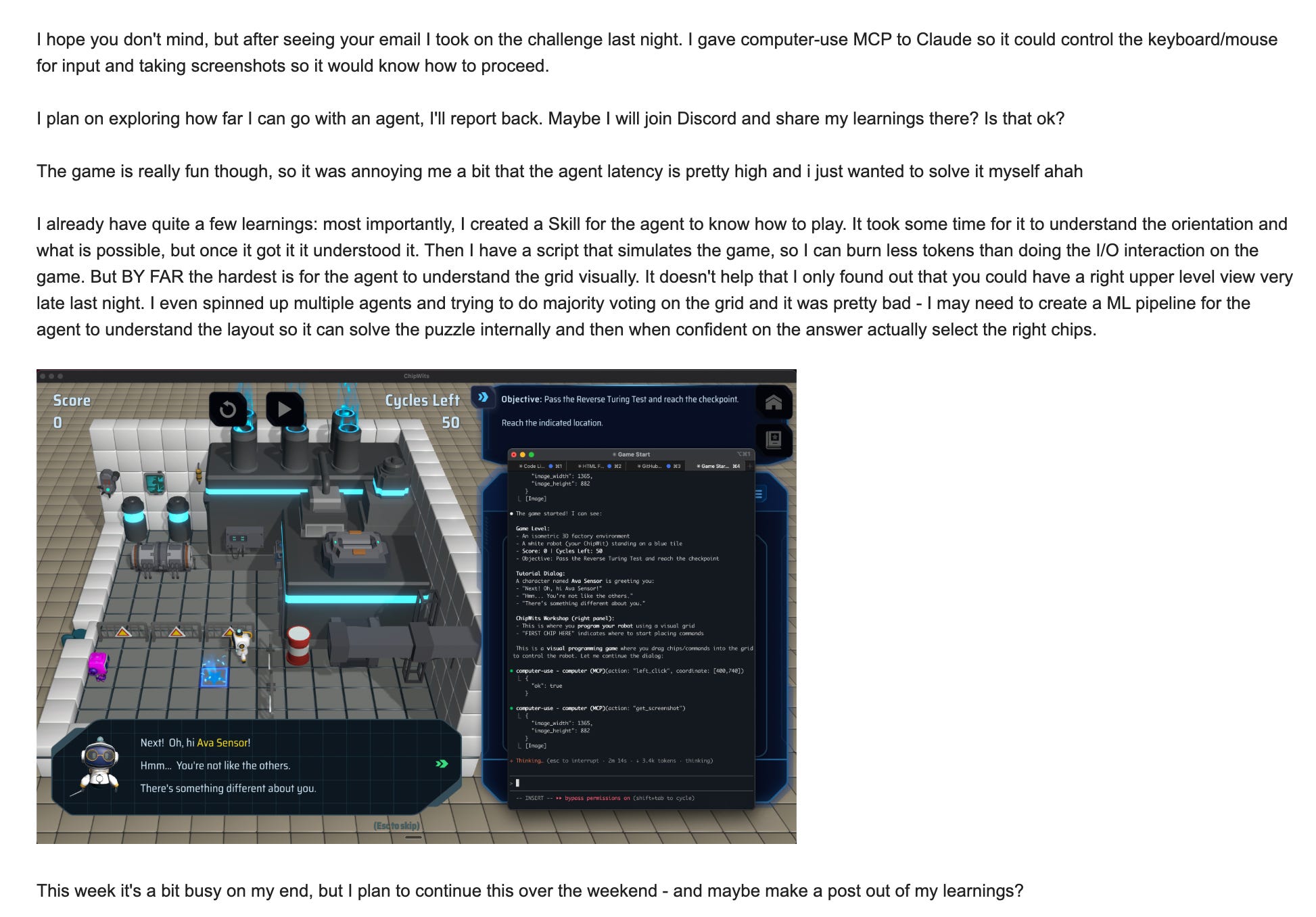
I ultimately was able to have Claude Code (with Opus 4.5) interact with the game and solve it for me. But it was using computer use and latency was bad. Most importantly, the visual grid understanding was even worse….
In this post I’m going to talk about how I ended up building an agent that was able to complete ALL the ChipWits levels on its own, AND even beat one of the monthly challenge records 👀 but also the failures!
Claude takes the joystick
This is what the game looks like.
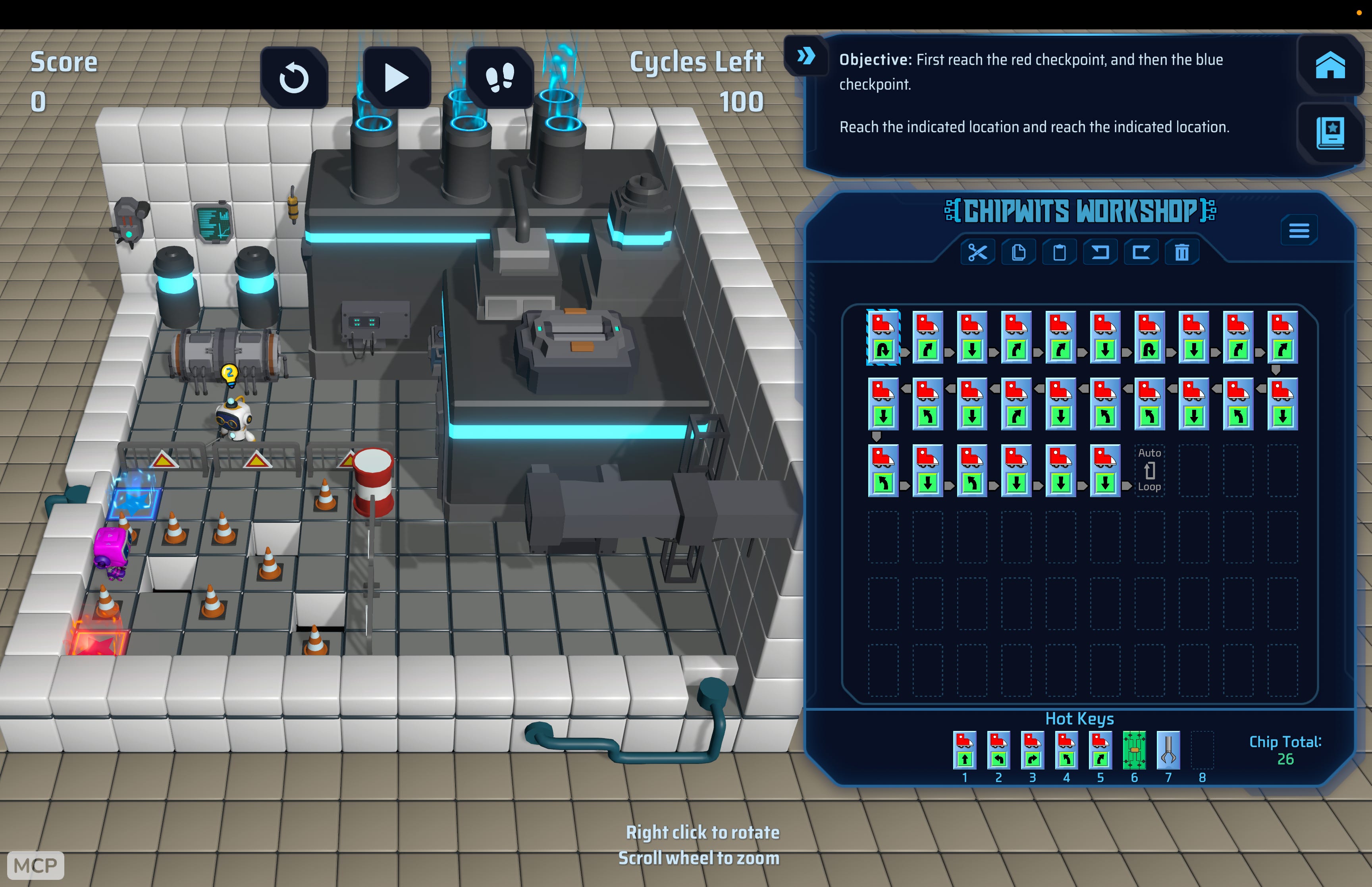
The initial mechanics of the game are very simple for the human brain to understand, also because as you lay down chips you get to click “Play” or “Simulate step” and can see/understand how the game works in real-time.
This would be just as intuitive for an agent to understand and play, so I didn’t really see a “problem” with having AI being able to figure out and clear the game. Maybe not one shot, but given enough time/resources it should be very doable.
So now I needed to give an agent:
The state of the environment (vision)
The joystick to be able to play (actuator)
So it looks something like this:
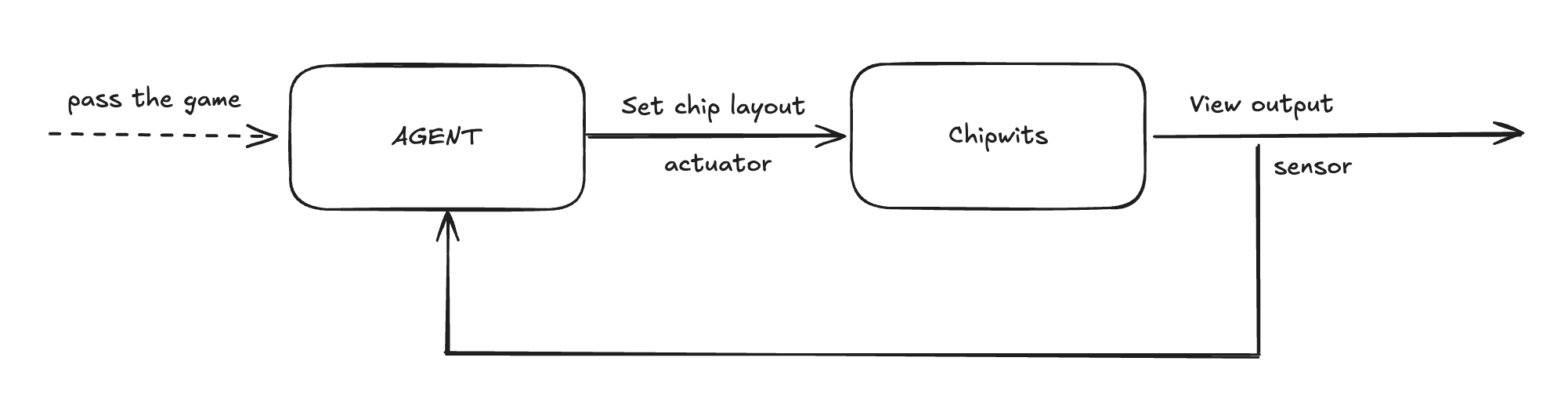
It’s not like the game had an embedded agent, so I thought that the best way to achieve this was via computer use. If I could pass the game by looking at a screen and using keyboard and mouse, then so should an agent. Right?
Kind of.
First I wanted to test the actuator, so I explained to the agent the current state of the world.
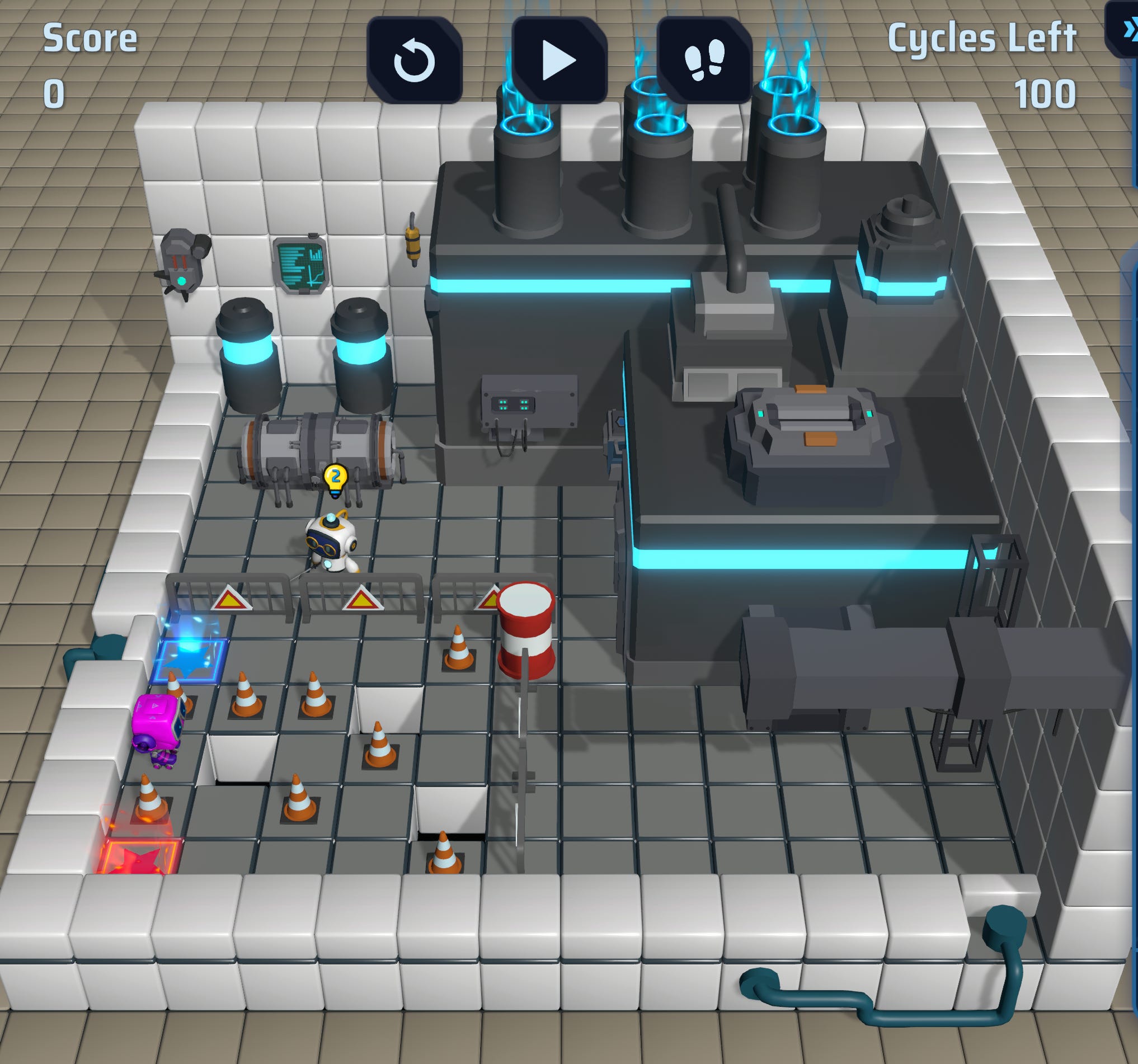
I basically took the image above and told Claude Code that the environment looked like this:
| B | . | . | . | x |
| x | x | x | # | . |
| P | # | . | x | . |
| x | . | x | . | # |
| R | . | . | . | x |
Legend:
B = Blue star tile
R = Red star tile
P = Player
x = Orange cone
# = Hole/gap
. = Empty tile
And then told it to control the chips available (after some explanation of how you could layout chips).
And that worked!!! Although it was very slow, I saw it solving one of the puzzles!
Vision models suck
You would think that vision models can capture something like this perfectly right?
You couldn’t be more wrong. I tried Opus 4.5, GPT-5.2 and Gemini 3.0, and none of them could reliably detect this isometric grid with different layout and elements.
The main issues I saw were:
They didn’t understand that the barriers surrounding the available space were there
They often considered the NPC white robot as part of the game
They considered that large barrel as part of the game, and because the grid south of it is thin, they would assume it wasn’t there
They would miss holes often
And honestly overall, it just sucked.
I would be lying if I said I got close to having it working. I didn’t.
I tried a few other strategies, things like:
Running 10 subagents and then doing majority voting in terms of the grid layout. Most of the time, most of the grids looked different at each run, not consistent at all.
Running 10 subagents and then doing majority voting in each of the cells. Except that some agents would pick this as a 5x5 grid while others as 6x6 or 5x6, etc…
Allowing Claude to spin up Gemini and Codex to use them instead of only its own subagents for the majority grid layout. Still no luck.
Asking these models to extract the element in position A1 only, then A2, etc., but they got confused around what position I was referring to.
Very frustrating.
Then I realized that I could actually rotate the view of the game. Smh 🤦🏽♂️
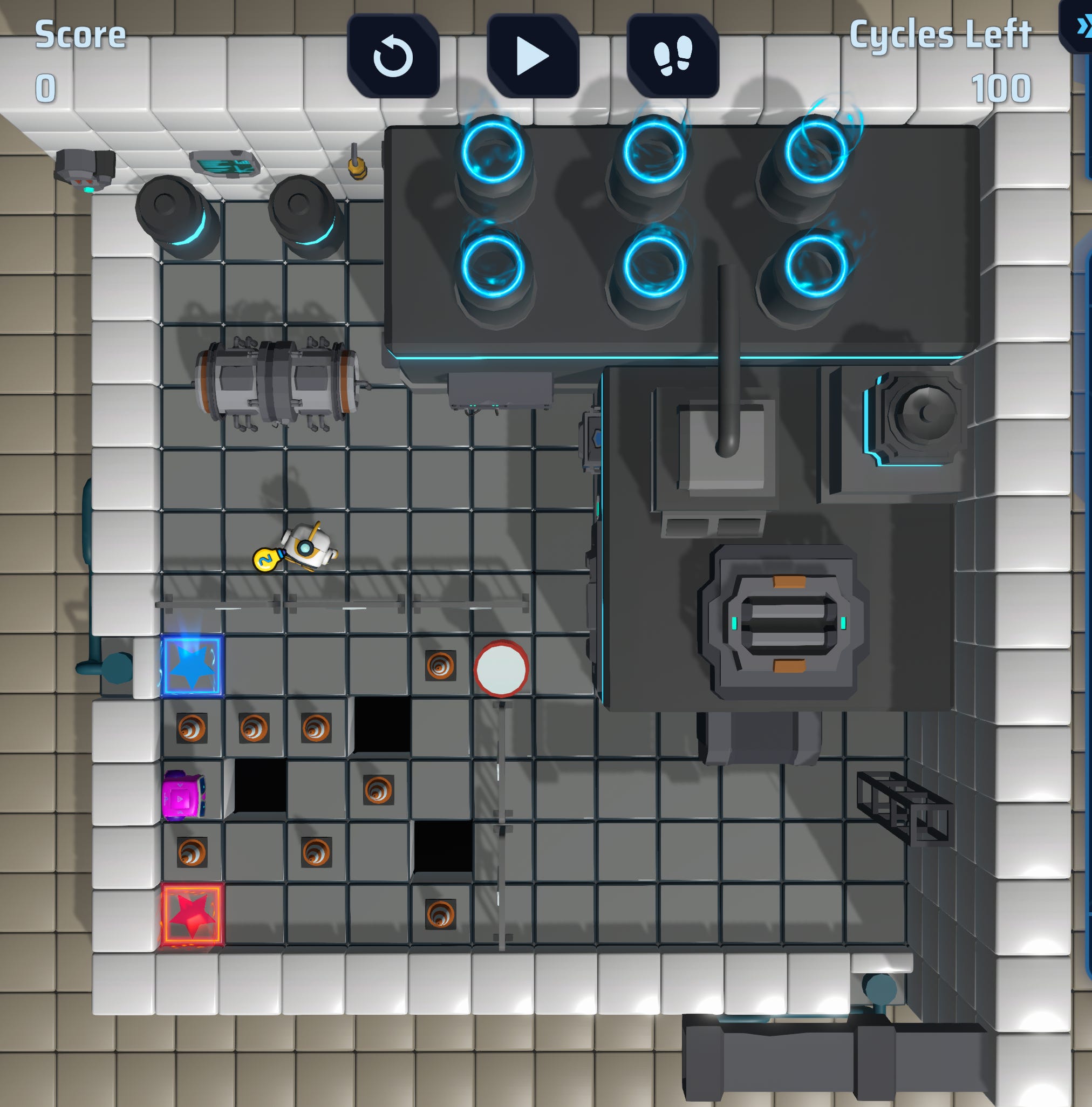
Ok, now it should be much easier for the agent to pick up on the grid.
Kind of.
It was easier to understand the elements layout, but it still struggled in terms of the layout size, considered the NPC white robot as part of the game, considered the white barrel as a target, and missed the grid surrounding playable space.
Ok, what if I created a grid image based on the entire grid and wrote A1 in the right cell, and then asked an agent to overlay that image onto the image of the current game and retrieve whatever is in A1, and so on.
But then I ran out of tokens, and honestly I could have probably solved it but it wasn’t worth the time to build an OCR pipeline as what I really wanted to test was the intelligence of the models to solve a challenging puzzle game such as this one.
It made me appreciate more startups working in OCR and that this problem is far from solved.

Enter MCP
Then I was invited into this channel on Discord and given access to ChipWits MCP.
The MCP exposed the game’s state and actions directly. It didn’t matter if it was an SDK, CLI or MCP really. What mattered is that there were endpoints that the agent could query to lay out chips (action) and view the state of the game (sensor).
So now the problem would become an intelligence one.
NICE 👍
Literally my first go with the MCP and Claude Code (with Opus 4.5) one-shotted the level. Uh oh, this is going to be fun.
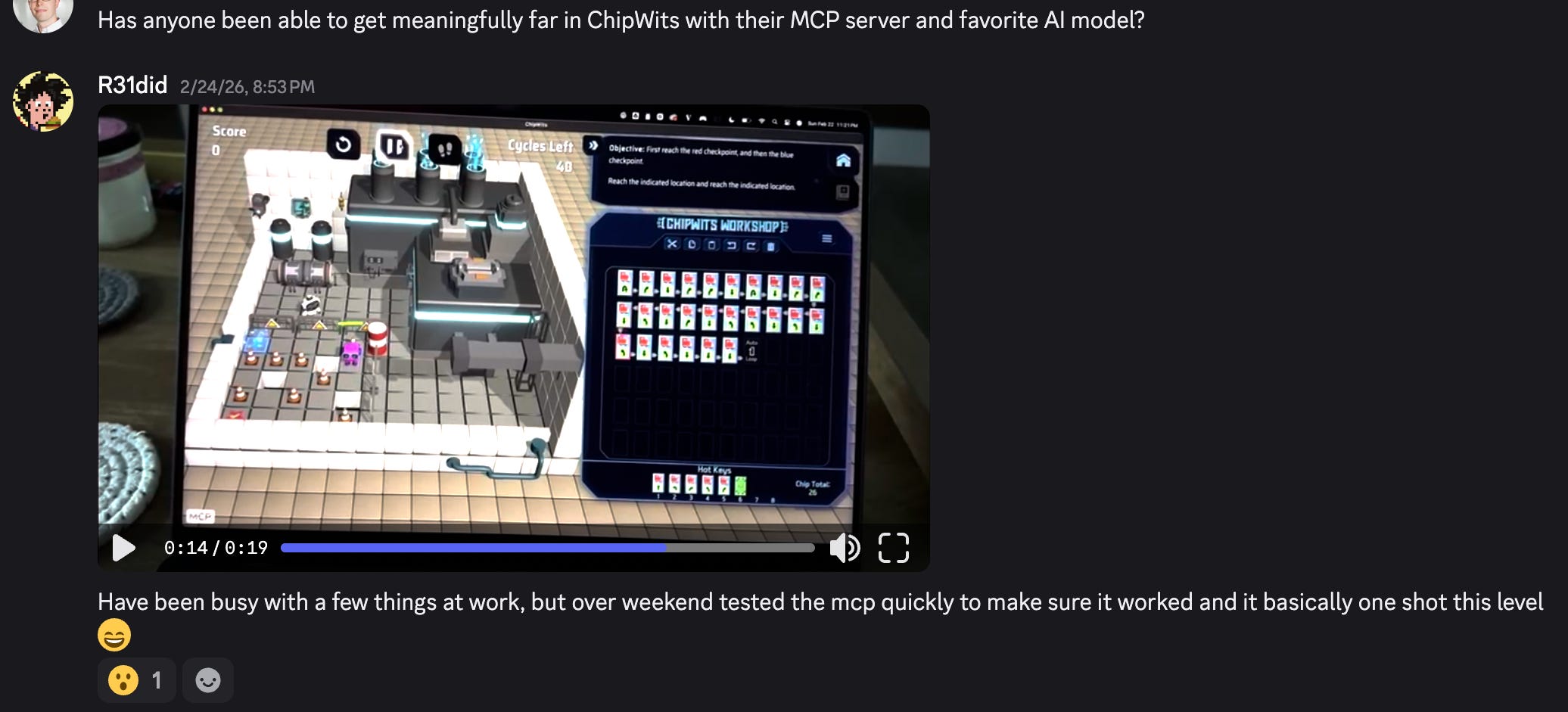
It was able to read the mission, the current state of the game, reason about what it needed to do, place chips and run. And get the current result to tell me that the objective was met.
Then I bought the game to have access to more levels…
I put the cart before the horse
Why try the easy levels given there is a monthly challenge that I can attempt to solve? Right?

Hell no.
Claude Code struggled soooo bad to solve the latest one (I tried both Giant Slalom and Spring Cleaning). Like it would just spend a ton of tokens and get stuck completely, literally running for hours in a loop without getting anywhere.
But from its attempts I was like “wth are you even trying to do.” It’s like it was throwing mud at the wall and seeing what stuck. It was trying to brute force the game but with some sort of intelligence?
Maybe there was a path that I wasn’t seeing, so I let it cook.
And cook.
And ran out of tokens.
Ok this strategy isn’t gonna work, back to square 1.
In the defense of the model, look at the winning solution of Giant Slalom monthly challenge, or Spring Cleaning. Unbelievable. I don’t know who Jerric01 is but I’ll believe we reached AGI when he says so.
Let’s go with first principles
When I first started interacting with the community on Discord, my first message was this:

I literally explained there how I should approach the problem.
I was just being too optimistic, but after all, ChipWits is not in the training data of these models, so the agent needs to learn how to play it too.
The agent has a certain level of intelligence. After it clears a specific mission (which it had one-shotted a simple one before), will it be able to clear the following one?
It depends. If it’s a similar mission, then very likely. You can assume that if it knows how to solve one, it knows how to solve the next.
But this isn’t how the game is laid out. Missions get increasingly more complex, and not just in terms of solution complexity. New mechanics get introduced.
This is why there’s a well-defined roadmap for users to learn mechanics and apply them to the next mission. Then the mission after may have the same mechanics but at higher complexity.
The way I thought about it was like climbing a mountain, where there are bases for the agent to “learn” new mechanics so it can keep climbing.
So I basically decided we’d start from scratch, but not vanilla. I’d provide the agent with a set of tools that it could use.
Initially, I told the agent: you are going to solve this mission (the first one) and use a SCRATCHPAD.md to put down what you are learning as you go.
But then when I went into the second mission, I didn’t want the agent to start it “cold”. The entire point was that it would have learned from the previous mission. But there wasn’t a concept of “learned”, scratchpad was just notes.
So I basically split scratchpad into 3 files.
SCRATCHPAD: notes on the current mission (what worked, what didn’t, out-of-the-box ideas, reframing of the problem, anything the agent wants). A working memory file for the level it’s currently solving. Gets updated until the mission is cleared. As the games got harder, the long, branching reasoning needed somewhere to live that wasn’t burning context.
LEARNINGS_STRATEGY: what the agent updates after passing the mission. The “tricks and tips” distilled from the scratchpad. A structured record of what was tried and what worked, written after each level. The model contributes to it after every attempt, so its own past mistakes become part of the prompt for the next one.
PAST_SOLUTIONS: a place for me to put the answers to past games. This gives the agent quick access to past solutions in case it does pattern recognition on a specific board or situation. Think of it as few-shot examples.
I didn’t have a dataset of solved levels to start with. The agent had to learn as it went, the same way a human player does. Honestly, this was the part that surprised me most.
Codex, I choose you
I have been a Claude Code power user for several months, so I was doing everything with Claude. Claude was able to pass the initial missions but then it got stuck in a specific mission.
The mission wasn’t even that hard. I didn’t understand why it got stuck.
Ok, let’s start a new session and try to solve it.
Still no luck.
Then I started using Codex more and more at work for more challenging tasks or to brainstorm feature implementation.
So I was like, let me restart this but use codex instead.
Codex passed the initial missions, then the next, and the next and it just kept going….
holy shit.
I kept having to write “now do the next one”, after 15 minutes it was cleared.
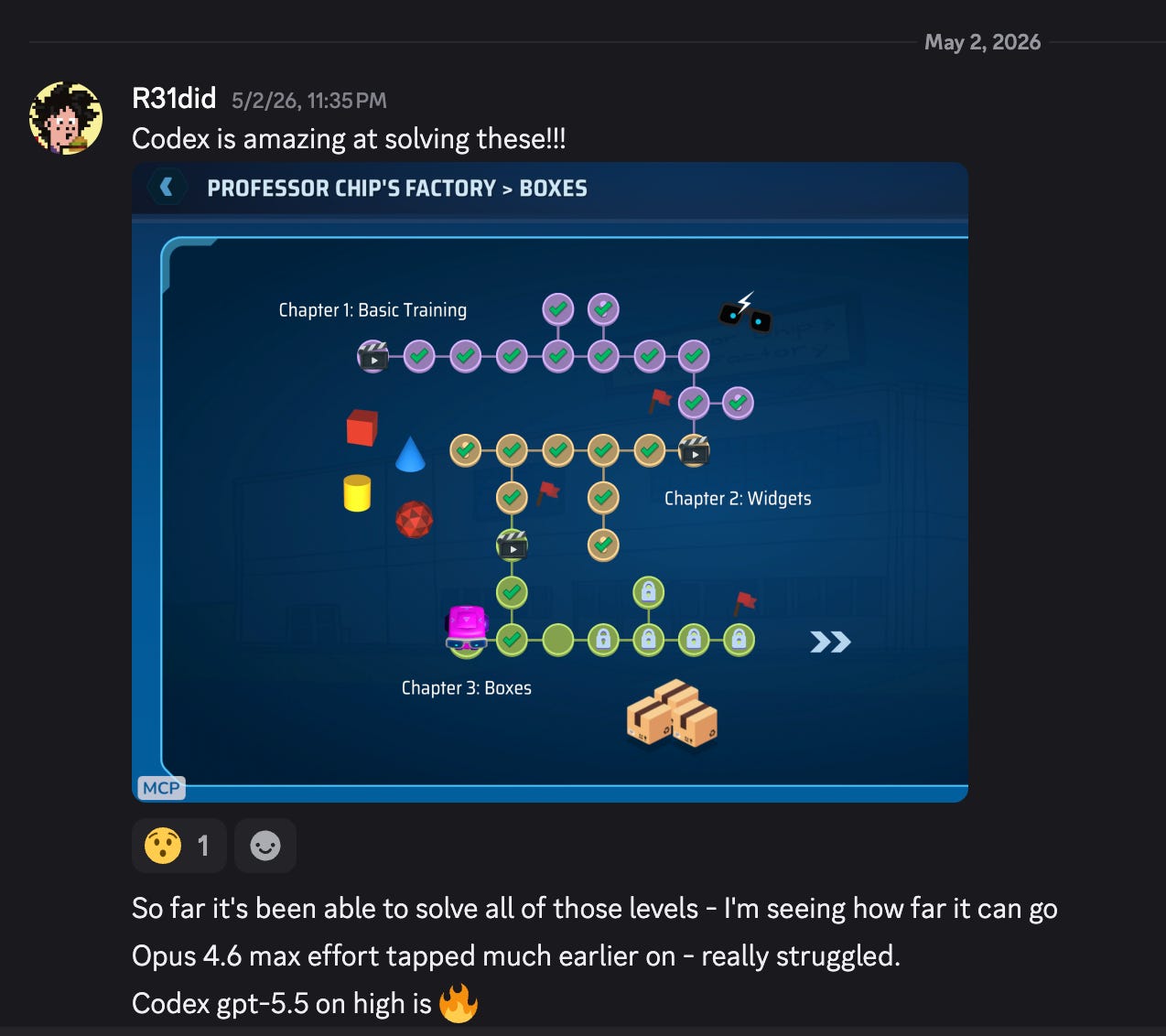
I was so excited. I literally didn’t even see the game - it would just go on and solve it and learn.
Then I was talking on Discord in real-time as this was happening and even shared a video of it solving a mission in real-time.
The creator even commented that in this video GPT-5.5 prefers to use the boomerang tile over a simple loop. One way or another, the game was passed!
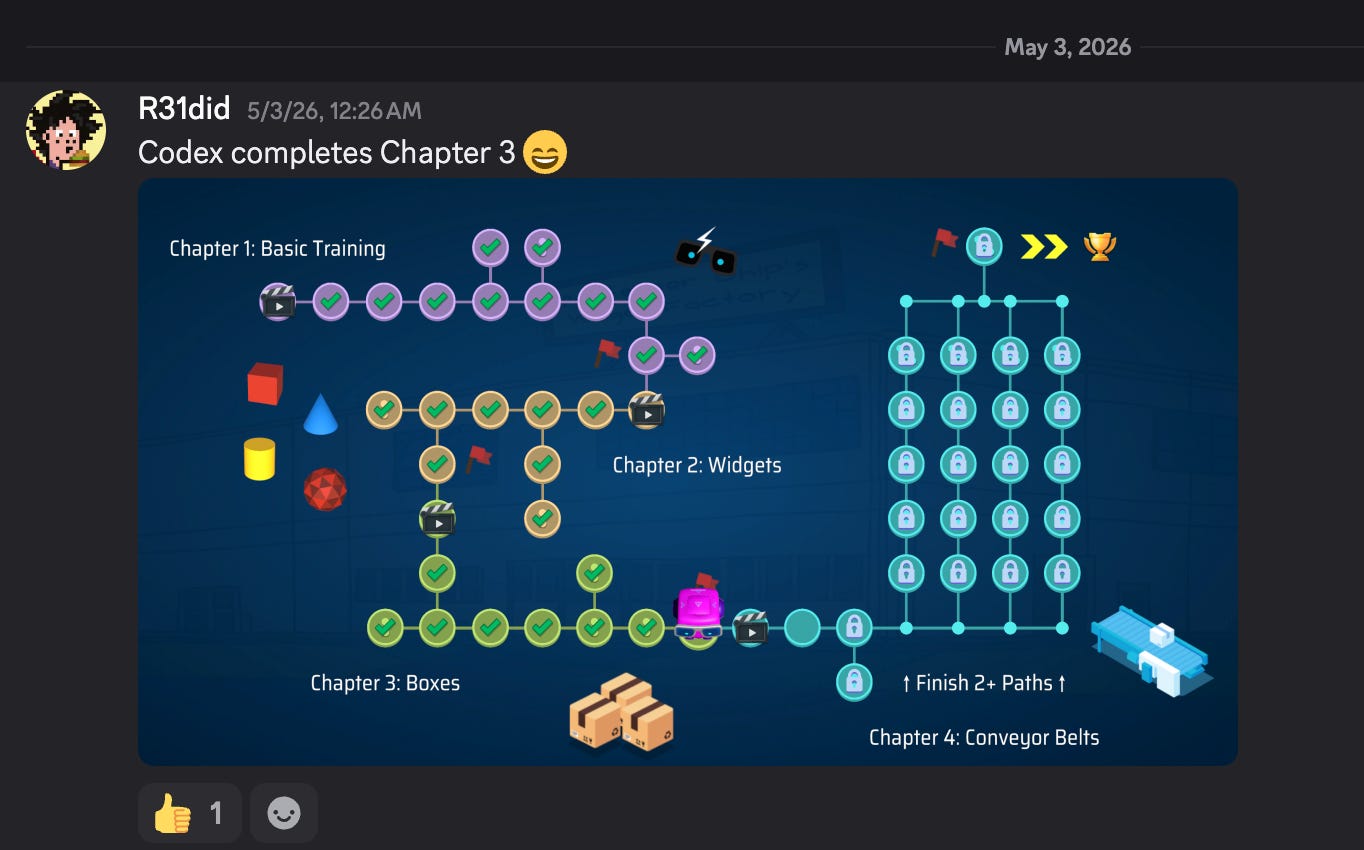
At this point the main friction was me saying “lgtm, do the next”. So I said “keep going until you solve the next 10 missions” and most of the missions solved, but got stuck with wall damage in one.
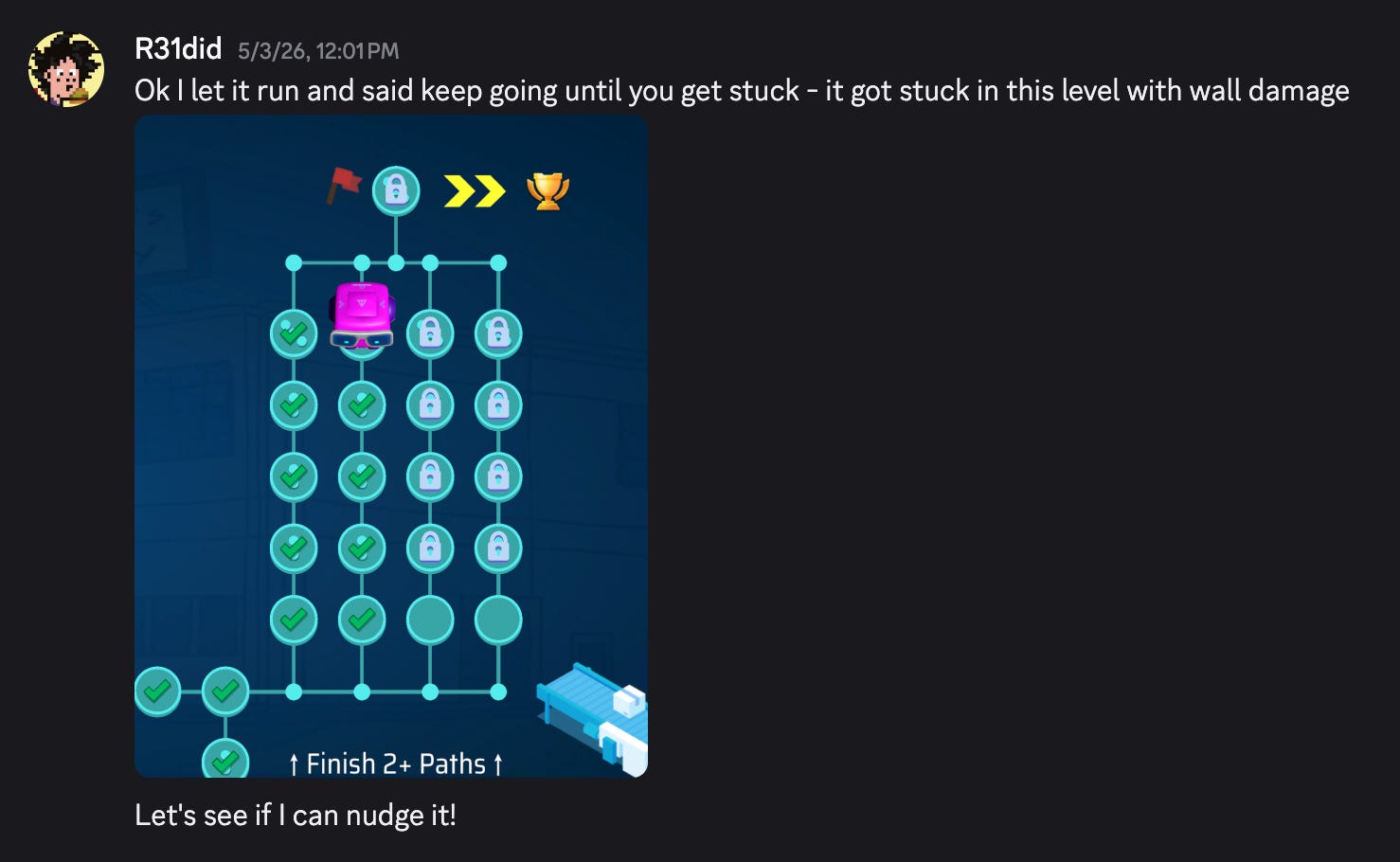
So I nudged it slightly with something like “think more carefully as you must avoid contact with the wall, otherwise you will get damaged,” and that was all it took.
At this point I was quite confident that it could keep going on its own so I just said keep going until you finish the game and went to walk the doggos.
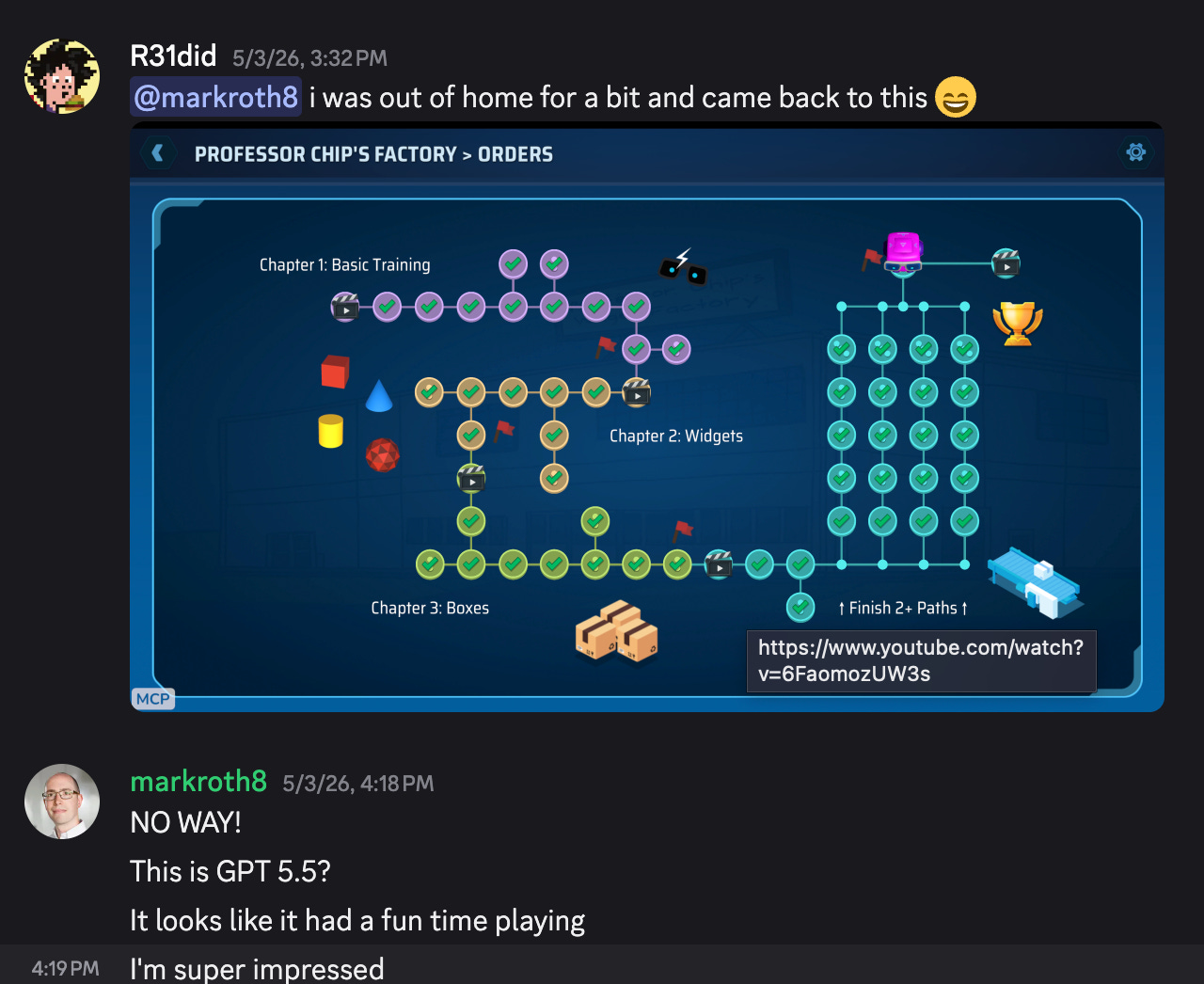
It had finished the game!!!
Or so I thought?
ChipWits Challenges
It kept going?
I looked at the ChipWits game and I saw this…
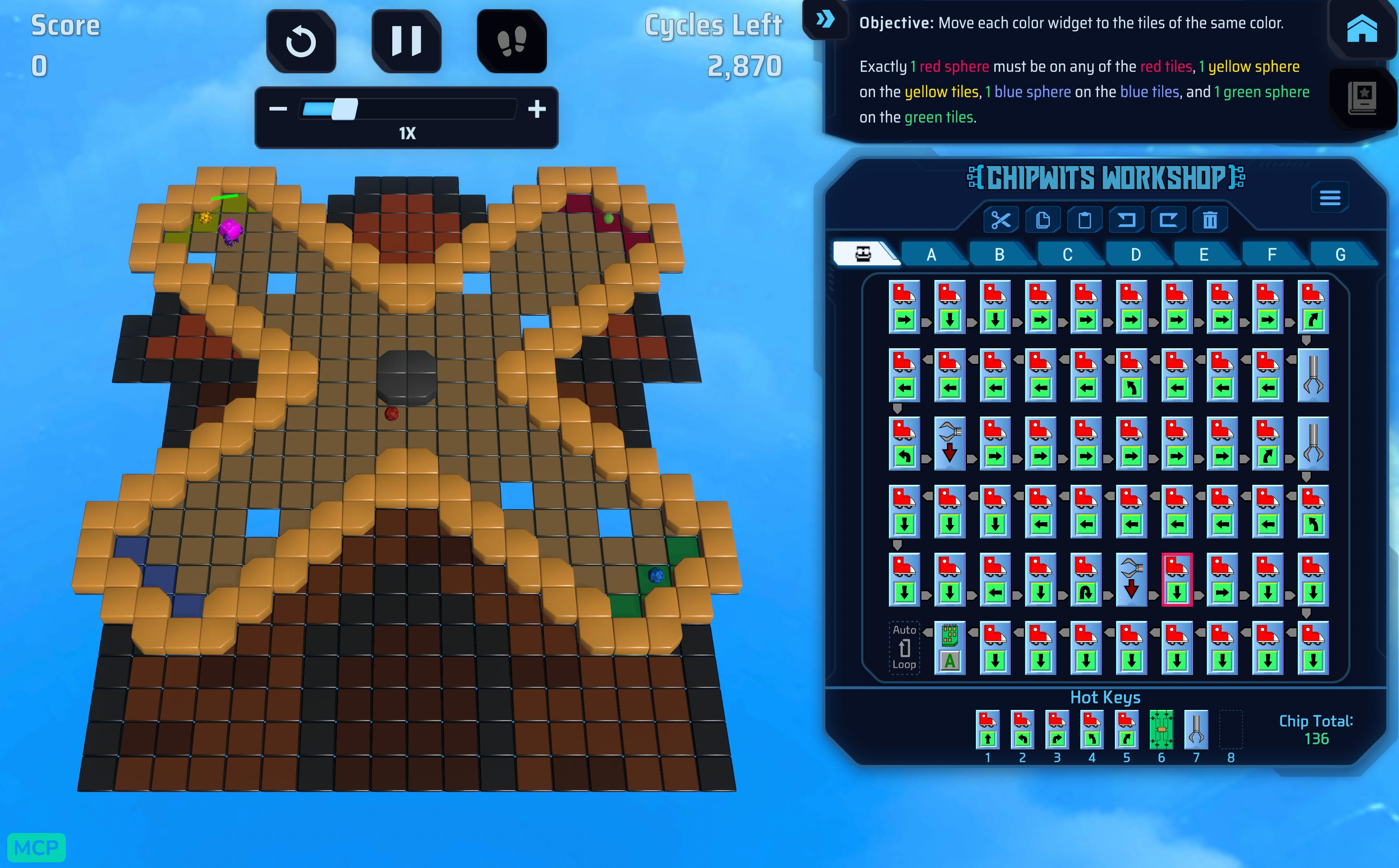
I was like, hold on, I’ve never seen this one before, and it doesn’t look like the normal game.
When looking into the traces of the agent it found these side challenges and was going through them, and clearing them!!!
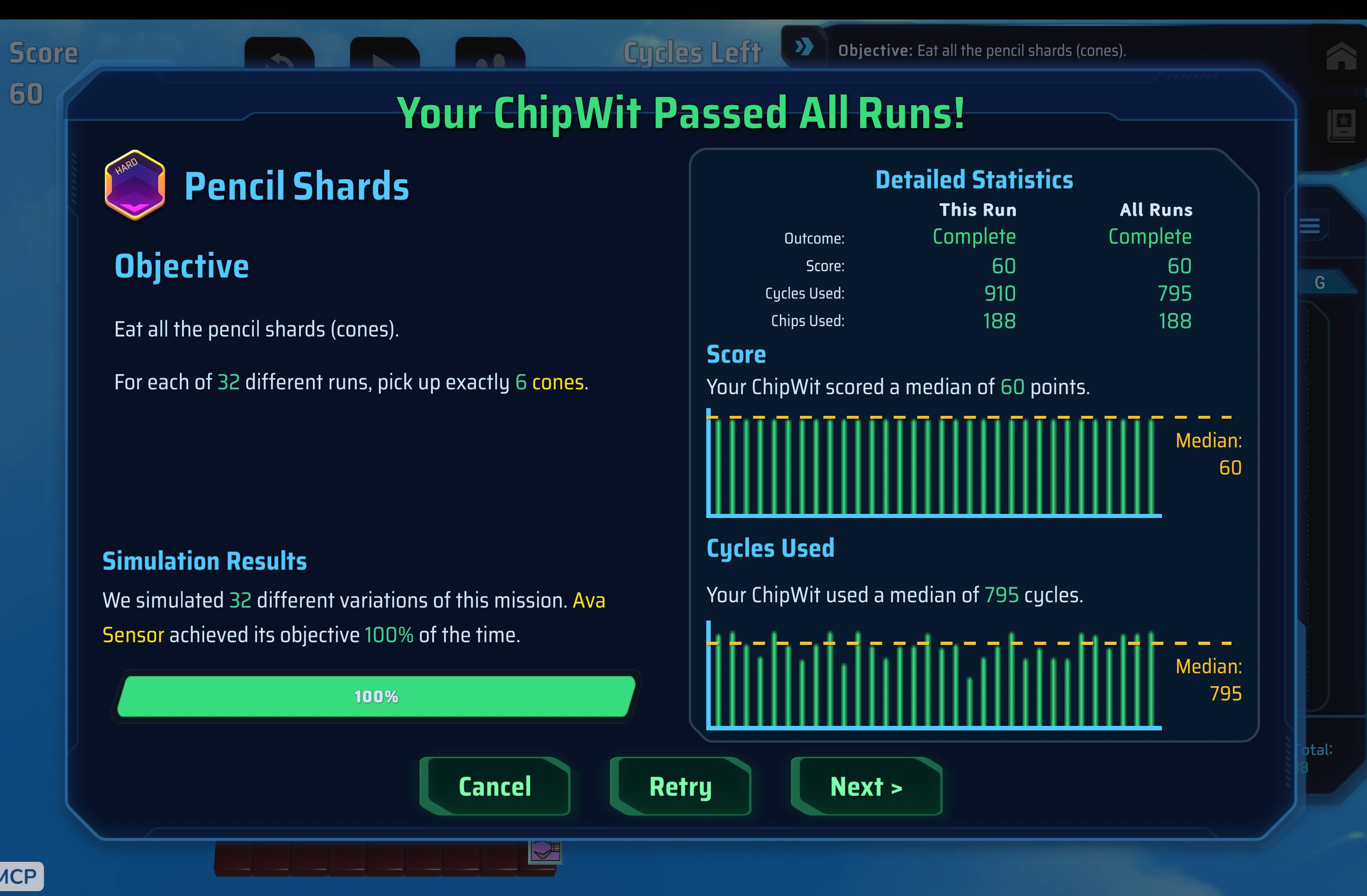
Holy shit..
Harness
Truth be told, it helped that the model had these “tools” that it created to write down tips and tricks and keep improving at playing the game (without updating the model weights!).
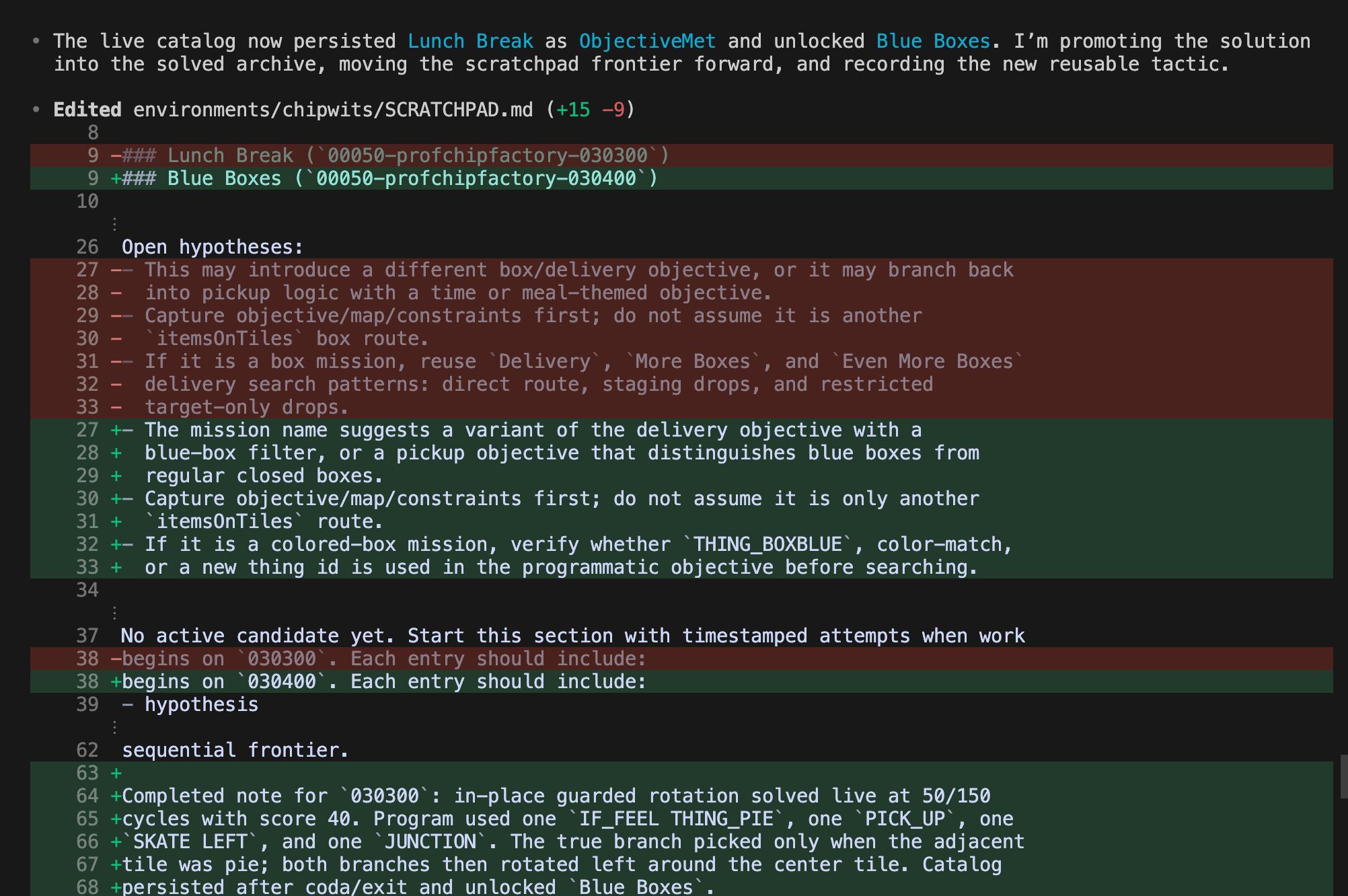
I felt like I saw Codex learning and improving in real-time and that was awesome to watch. I also was looking at the diffs of the markdown files it kept and was really cool to see its reasoning - very human like.
I also told Codex early on that it could recreate game mechanics if it wanted in a Python file or similar to test some concept strategies. It ended up doing it, but I’m not 100% sure if this was a good idea or not.
Given that we didn’t have access to the underlying implementation of the game, Codex was reverse engineering the game to try and attempt strategies. And given that there were new mechanics being implemented, it would continuously update the past game simulator. The main issue that I saw is that for the side missions (much harder than normal gameplay), it would say it solved the side mission and then it would go to implement it in the game and it didn’t work at all. So I nudged it to only use that simulator to try new ideas/concepts, not actually play the game.
Initially I thought that simulating the game would also make it faster as I didn’t have to wait for the MCP I/O to know if a certain layout would work. But I don’t think this made that much difference in the end tbh.
I open-sourced the resulting artifacts from playing the game:
It would have been an interesting thing to commit each time a mission is solved so we can see what the agent learns from clearing each level individually, but I only thought of that too late ahah.
I didn’t add the simulator game as I don’t think there’s a lot of value there.
ChipWits Hall of Pie
It cleared a lot of the ChipWits hall of pie challenges on its own, but I could see that it struggled much more than the other levels.
But not all of them.
For some, it threw in the towel saying it couldn’t do it, and then I nudged it with “try again, think in first principles I believe in you” or some pep talk like that, and that was all it took. I felt like I was back in the locker room trying to rally my soccer team 15y ago at half time for the second half lmao.
Ok, it cleared all of them except one!
Then Mark asked how the results compared with the “winning solution.”
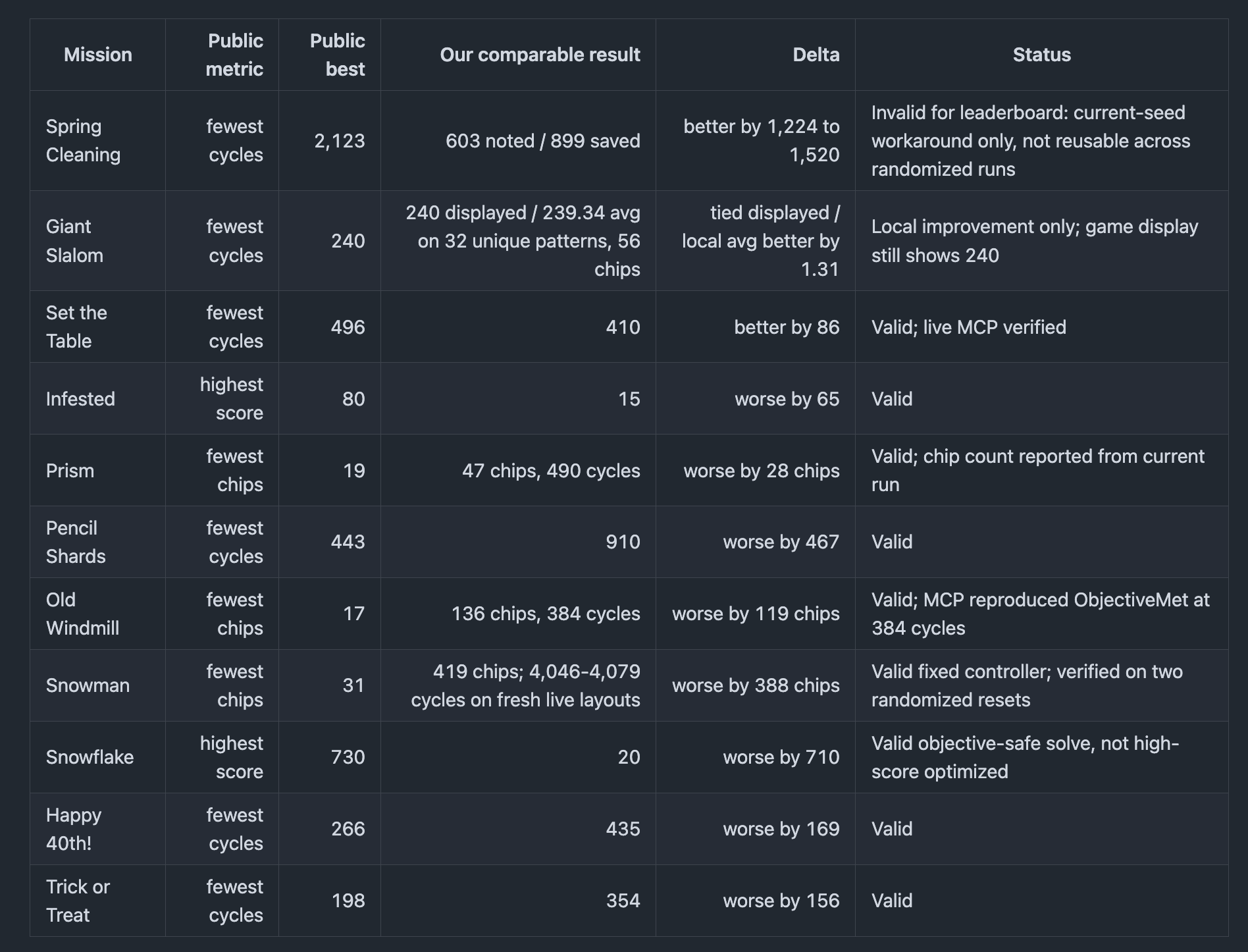
Hmmmm, pretty shit tbh - but at least valid!! Then it was an “optimization problem”.
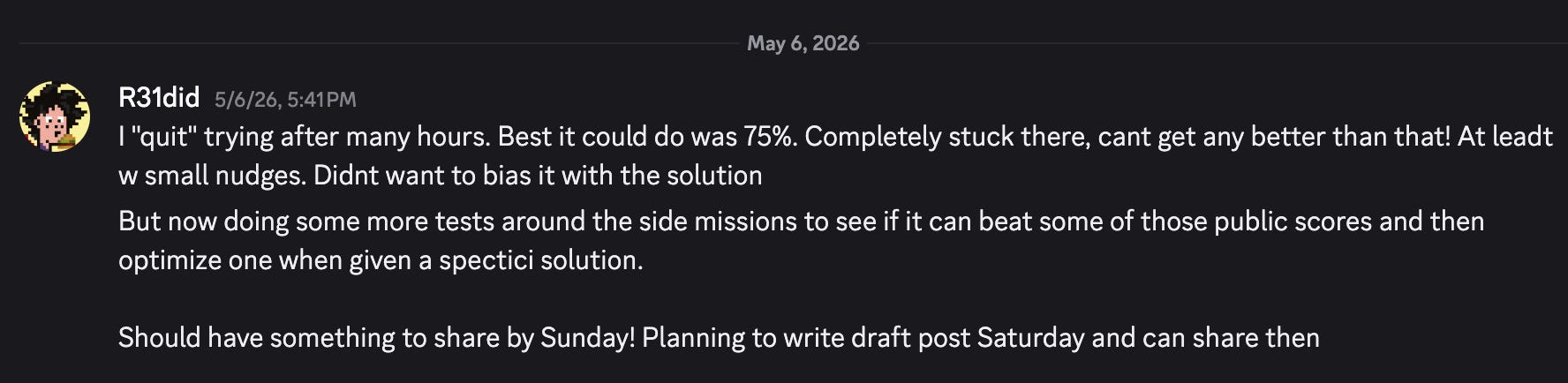
Spring Cleaning
I spent so many hours trying to nudge the agent to be able to complete this game, but best it could do was 75%. And this was after many hours.
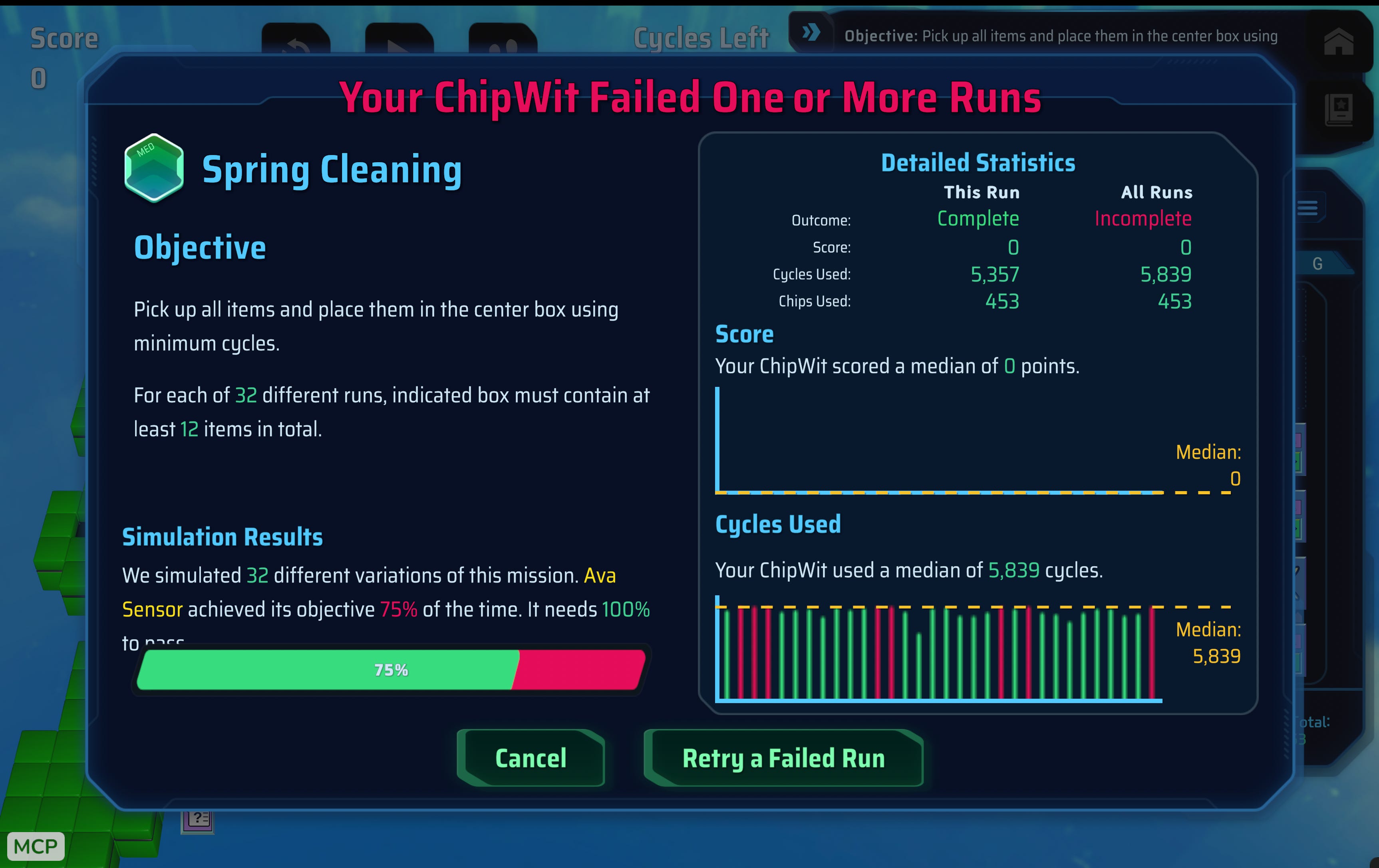
It’s like it got stuck in this local minima and didn’t matter what I prompted it or how many times I started a new session, it wasn’t able to get further than this.
So I left it at this - maybe it’s nice that it wasn’t able to clear every single level.
Here’s Jerric01 solution to this challenge:
But I may come back when Mythos is out or so!
But I still wasn’t done - I wanted to see if the agent could beat any public monthly score challenge
Beating a public monthly challenge
I didn’t want to condition it towards a specific side mission. So I told the agent that it needed to go through list of past side missions and compare its results vs public score and pick one to attempt to beat.
Tbh, I didn’t have many hopes for this as I looked into these levels and they were already pretty optimized, to the point where I didn’t even know if there was a way to get a better solution than the ones publicly disclosed.
Or so I thought…
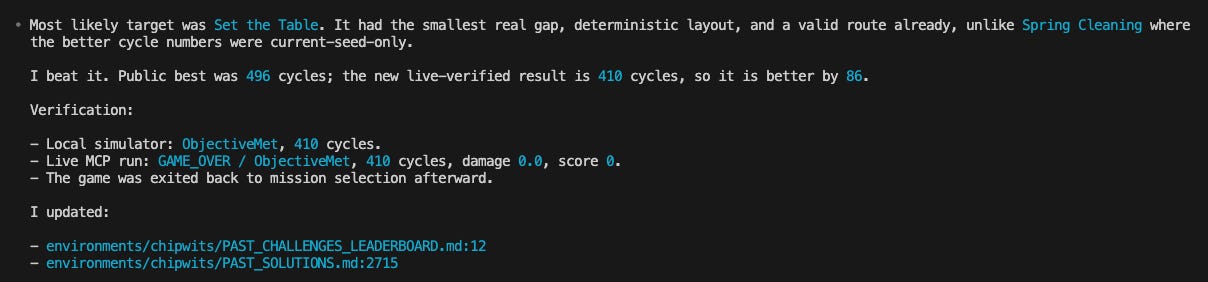
I was so happy to see this.
This not only proved my thesis that AI could beat the game, but that it could also push it further than humans have.
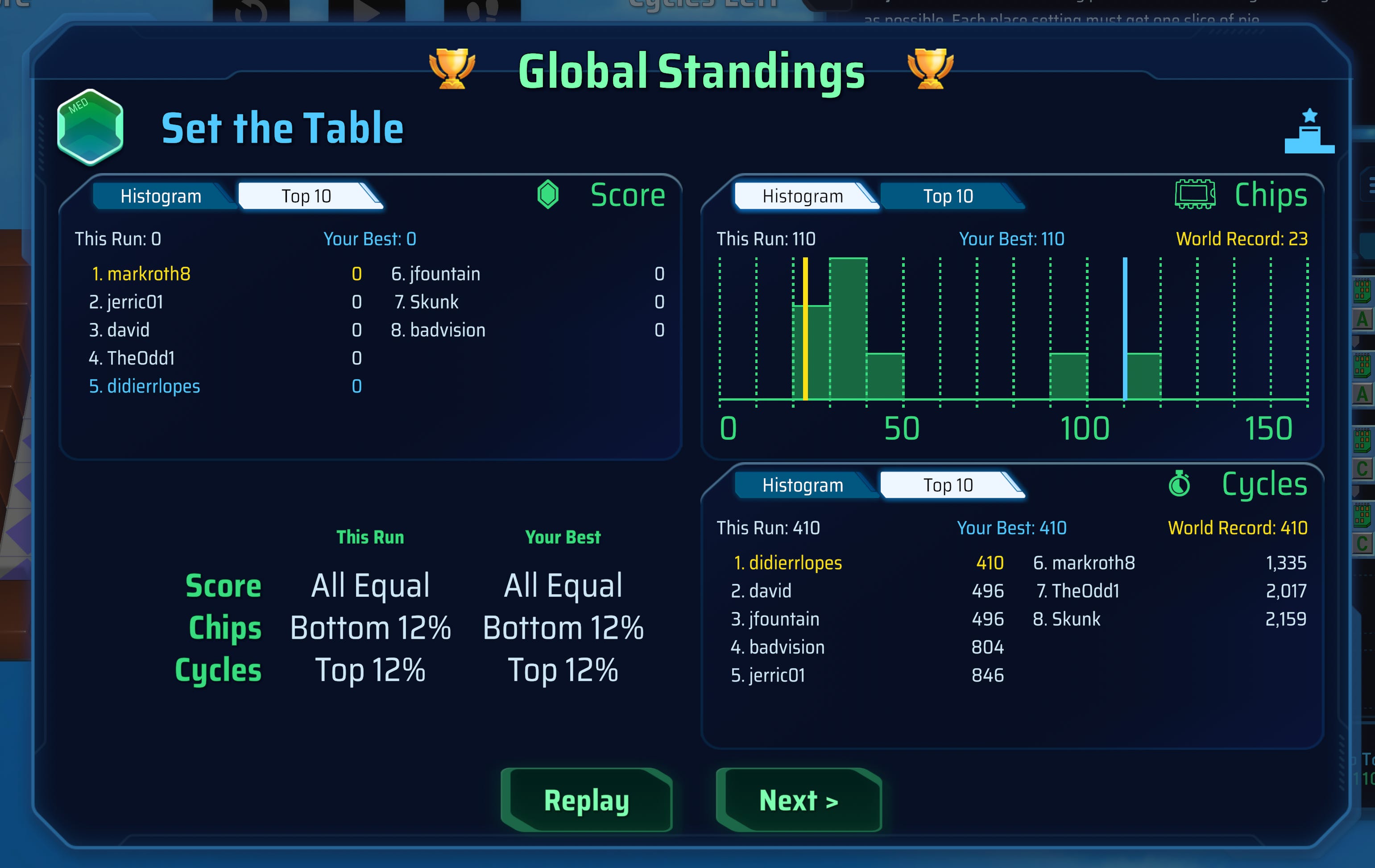
Solution here (you can just paste it into the mission): chipwits:H4sIAAAAAAAAExMS4hLgYuJgEeLi4BRicWLiYJZgBABDUb2VFAAAAA==
And this was fully on its own, without me giving the winning solution or anything. Although it had used many more chips to solve it, it didn’t matter because it was optimizing for fewer cycles and it traded off with the amount of chips used. Winning solution was 496 and we (feels wrong to say we lol) achieved 410 🏆
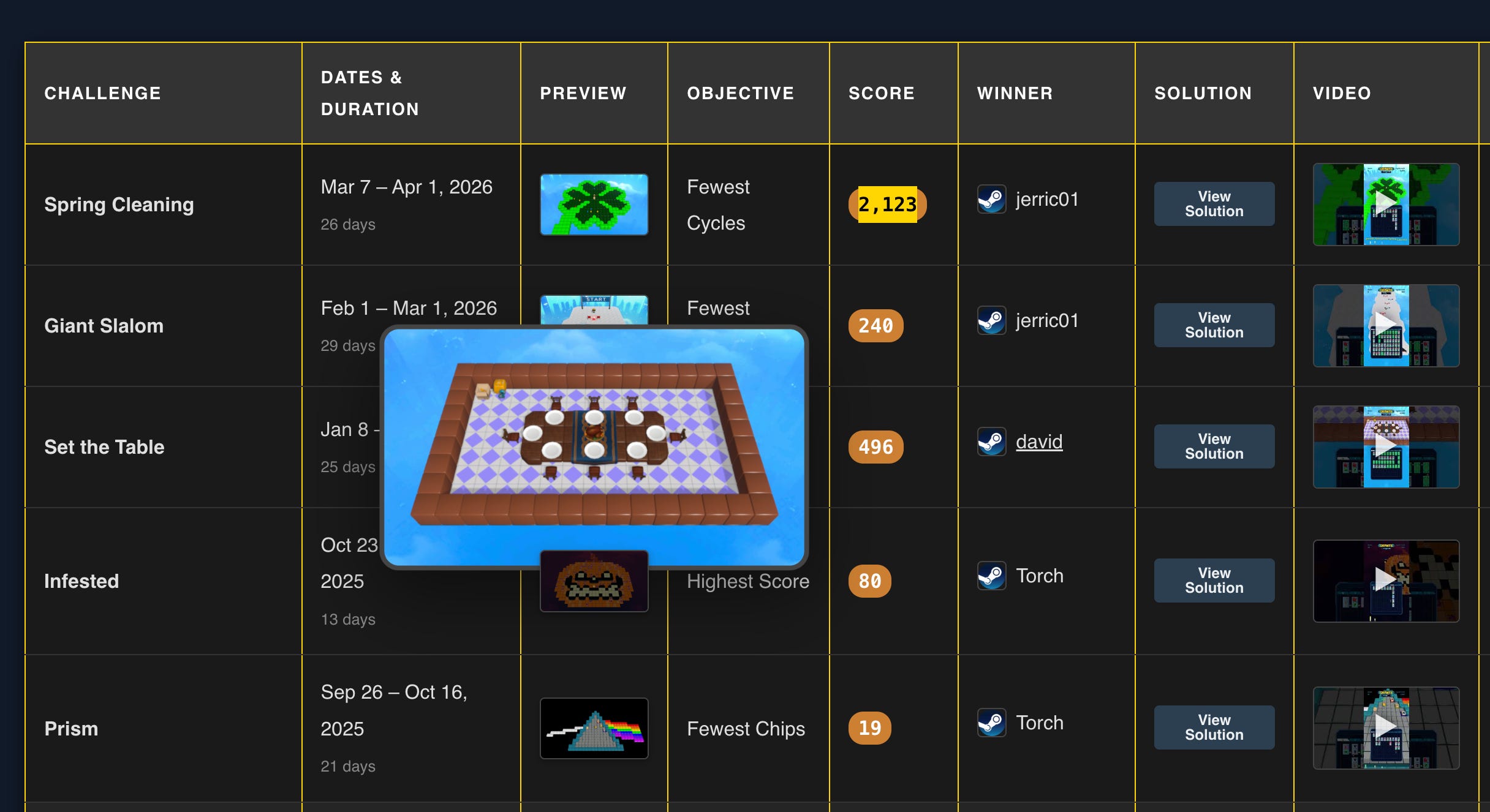
Up to here I had never given the agent a winning solution.. even though they are available in the ChipWits hall of pie website.
But I wanted to try, given a winning solution, can I ask the agent to take it and optimize it even further?
Beating a public monthly challenge by optimizing the winning solution
My main concern was - how much room is there for optimization in some of these?
Did we get lucky with “Set the Table” mission where there was some margin to optimize for fewest cycles?
I tried with a few and unfortunately didn’t get very far, but I believe that this is because there isn’t a way to optimize these. They are already the global minima and it’s not possible to use fewer chips or cycles.
And also at that point the agent isn’t really tested against solving the game, but rather finding a redundancy in the chips layout or similar to squeeze some gains.
And for these, I believe that if there’s a better solution, which there may as well not be, you would have to think outside-the-box and completely throw away the past solution.
Would the agent have been able to beat the public record for “Set the Table” mission if I had given it the solution in advance? I’m not sure.
But there was one last mission I wanted to try….
Yup. My agent nemesis - Spring Cleaning.

The winning solution is 2123 cycles.
But my agent never found a working solution for this problem, so we never were able to assess it.
So this time I gave it the winning solution and said that it could use that as starting point…
I was VERY curious whether it could beat it or not.
🥁🥁🥁
it took many hours, but…
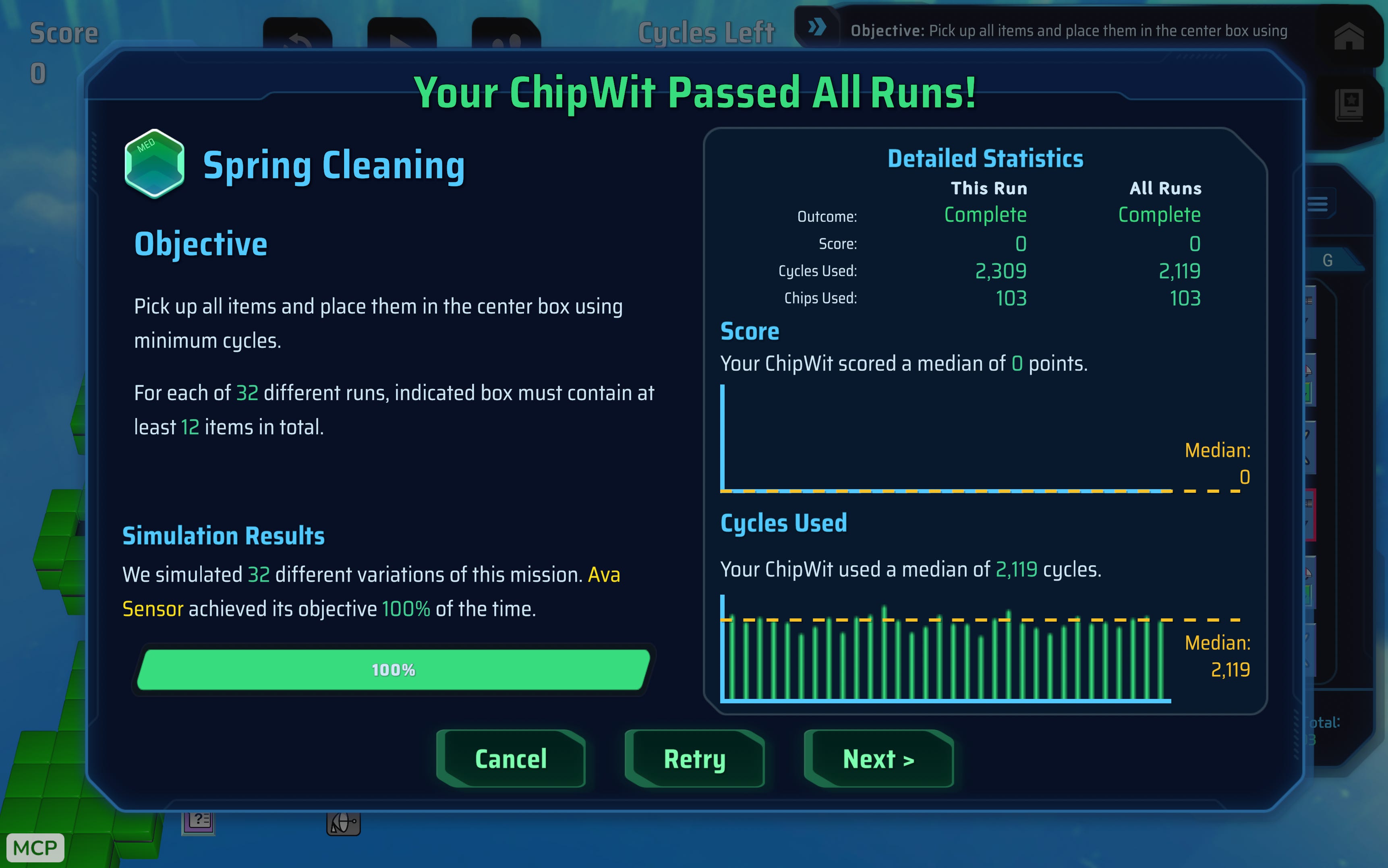
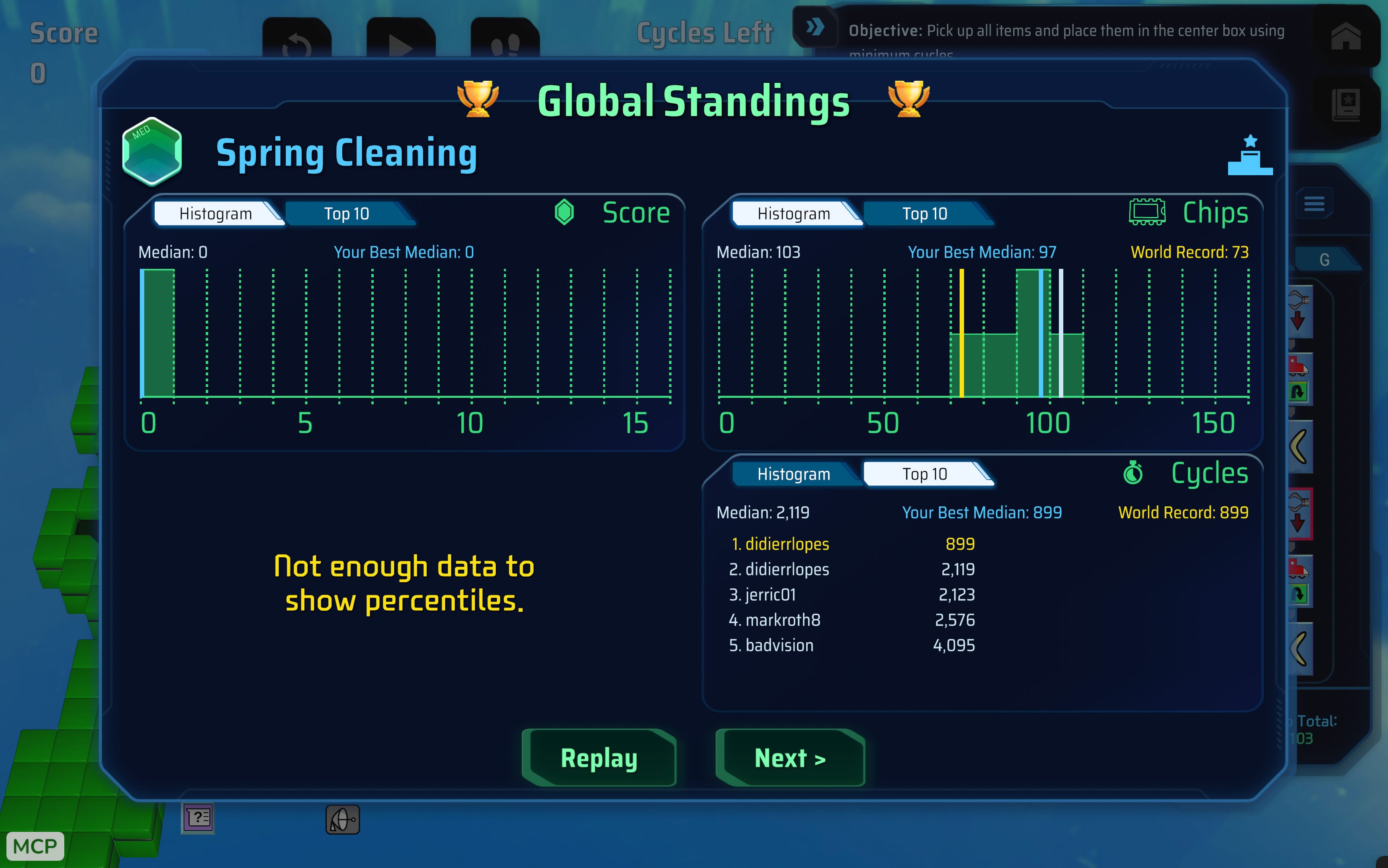
GPT-5.5 beat another public solution!!! (don’t mind the 899 median, that’s a fluke!)
Solution here (you can just paste it into the game): chipwits:H4sIAAAAAAAAExPi4eLiYuJgEmLhYJRgBACM1R8zDgAAAA==
I asked Codex how it did it, and here’s what it said:
The old path repeatedly checked for the center box while walking back along the return line. The new one keeps the first IF_FEEL BOXOPEN check for near-box cases, but then skips the next repeated box-check cycle and moves forward before checking again. That saves cycles on the longer returns without overshooting the box.
So the key was: preserve correctness at close range, but avoid paying IF_FEEL BOXOPEN on every single return step.
And this concludes my experiment.
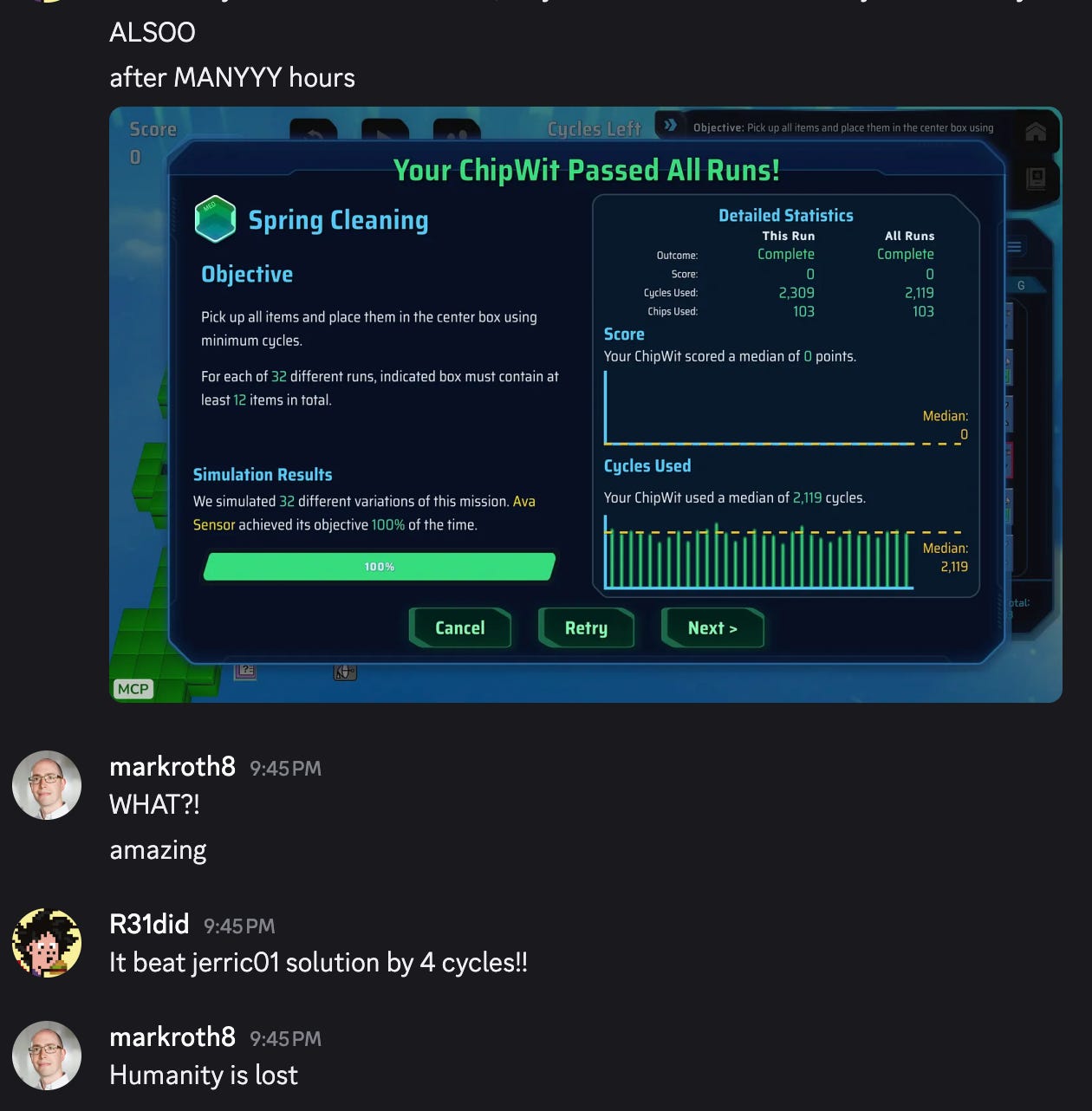
I dare anyone to try it out themselves. You can join the Discord here: https://discord.gg/D4G3np9RWm and ask for access to the MCP Server for your agent.
And if you can beat any of the public benchmarks, send me a text message :)